
ロボット工学のブレイクアウトの瞬間
August 7, 2025





私たちは今、ロボティクスの新しい時代を迎えようとしています。基盤モデルやトランスフォーマーベースのAIの進歩、そしてハードウェアのコスト低下と性能が劇的に向上したことにより、この分野はこれまでの領域が狭く、タスクに特化した自動化から、より野心的な「汎用的なロボット知能」へと進化を遂げています。
市場もこの動きに注目しています。
ロボット企業への投資額は2024年に70億ドルを超え、Figure(シリーズBで6億7500万ドル)、Physical Intelligence(シリーズAで4億ドル)、Skild(シリーズAで3億ドル)といった大型の資金調達が目立っています。
世界のロボット市場は、ロボットが汎用的な能力を獲得し、産業界からサービス部門、そして一般家庭へと拡大するにつれて、今後5年間で飛躍的に成長すると予測されています。
その成長の内訳は以下のとおりです。
- 産業用ロボット:2024年には340億ドルと評価され、製造業、倉庫ロジスティクス、建設業における自動化の深化により、2034年までに600億ドルに達すると予測されています(CAGR約9.9%)。一部のアナリストは、今日の市場規模はこれよりもはるかに大きく、さらに積極的な成長を遂げ、2029年までに2,280億ドルに達すると予測しています。
- サービスロボット:2023年には420億ドルと推定され、医療、ホスピタリティ、セキュリティ、物流・フルフィルメントに牽引され、2029年までに約990億ドルに成長すると予想されています(CAGR約15.9%)。これは、ロボット工学の分野で最も急速に成長するカテゴリーになると見られています。
- 消費者向けロボット:規模は小さいながら急速に成長しているセグメント(2025年には約140億ドル)は、有能で手頃な価格の家庭用ロボットが普及するにつれて、2030年までに290億ドルに成長すると予測されています(CAGR約15.5%)。現在の導入の大部分は、家庭用掃除ロボット、パーソナルコンパニオンロボット、ロボット玩具です。2030年までには、ヒューマノイドや新しいフォームファクターが消費者によって使用され始めるでしょう。
汎用ロボットシステムは、複数のユースケースや業種に適用できるロボットの登場を可能にすることで、これらのカテゴリーの境界線を曖昧にし、市場をさらに拡大する可能性があります。
私たちは、ロボティクスエコシステムが発展すると予想しており、ロボット基盤モデル(Robotics foundation models, RFM)、フルスタックのハードウェア/ソフトウェアソリューション、およびロボティクスツール(例:ロボット学習データプロバイダー、シミュレーションプラットフォーム)を開発するチームに投資することで、この成長を支援できることを嬉しく思います。
私たちは過去7ヶ月間、ロボティクス市場を深く掘り下げ、この分野で働く最も優秀なイノベーターや専門家数十人と話をしてきました。これらの対話を通じて、私たちはロボティクスへの投資のためのフレームワークを開発しました。それは、この分野がこれまでどうであったか、そしてどこに向かっているかに基づいています。
私たちは分析を2つの部分に分けました。この記事では、汎用的なロボット知能の実現に向けて産業を前進させている技術に焦点を当て、今こそロボティクスにとって絶好のタイミングである理由を説明します。今後出される二つ目の記事では、この新興市場で「本物」を「ノイズ」から見分け、世界を変える可能性を秘めていると私たちが信じるロボット企業を特定する方法を説明します。
私たちの関心とこの分野の理解に貢献したロボティクスに関する公開コンテンツ、特にCoatue、Colossus、SemiAnalysis、Salesforceからの洞察記事に敬意を表します。
それでは、早速掘り下げていきましょう。
現在の状況
歴史的に見て、ロボティクスの進歩は遅々としていました。その理由は単純で、解決するのが非常に難しい問題だからです。しかし今日、私たちは汎用ロボティクスに向けた数十年におよぶ旅路における転換点を迎えています。現在開発されている技術は、産業製造業や物流におけるロボットのより広範な導入を促進し、ロボティクスが小売、医療、ホスピタリティなどの新しい分野に拡大するのを助け、そしてロボットを消費者の家庭に持ち込むでしょう。これこそ、ロボット工学革命における最後のフロンティアであると私たちは考えています。
生成AIのイノベーションのペースが、ロボティクスのブレークスルーに対する楽観的な見方を新たにしている一方で、ロボットの商業化は依然として非常に複雑な課題です。成功には、ハードウェア設計と製造、サプライチェーンロジスティクス、そして堅牢で汎用的なロボット基盤モデルの開発など、複数の分野にわたる卓越性が求められます。ロボティクスチームは、これらの主要な分野すべてにおいて、早期に、そして多くの場合、高いリスクを伴う戦略的な決断を下す必要があります。企業が特定のハードウェアやモデルアーキテクチャにコミットすると、方向転換するにはコストがかかり、困難になります。
では、なぜ今が過去のロボティクスへの熱狂の波と異なるのでしょうか? 以前の取り組みが脆弱なソフトウェアと高価で柔軟性のないハードウェアによって制約されていたのに対し、今日のシステムは大幅に改善された基盤から生まれています。私たちの見解では、3つの主要な分野がこの変化を推進しています。
- スケーラブルなデータ
- 汎用的なAIモデル
- 高性能で手頃な価格のハードウェア
各分野で最近大きな進歩が見られました。タイミングが正しい理由を理解するために、何が変わったのかを探ってみましょう。まずは、真にインテリジェントな現実世界のロボットを構築するための基盤となるデータから始めます。
1) データ

今日のロボティクスにおける最も差し迫ったボトルネックの一つはデータです。大規模言語モデル(LLM)は、すぐに利用できる膨大な量のインターネット上のテキストデータで学習されましたが、ロボットを学習させるための同等のデータソースは存在しません。今日、ロボティクス研究者や開発者は、いくつかの学習データソースに依存しています。シミュレーションデータ、遠隔操作データ、人間のビデオデータ、そして導入されたロボットからの実世界データです。これらのデータタイプは、アクセスの容易さ、スケーラビリティ、および有用性の点で異なります。人間のビデオデータとシミュレーションデータは、スケーリングやアクセスが容易ですが、ロボット学習の特定の側面にしか役立たない可能性があります。一方、遠隔操作データや導入されたロボットからの実世界データは、スケーリングやアクセスが困難ですが、より価値があります。以下は、私たちが話を聞いたロボティクス専門家が各学習データソースをどのように見ているかの内訳です。
シミュレーションデータ
ロボティクスにおける従来の考え方は、シミュレーションデータはロボットに移動タスクの実行方法を教えるのに優れていますが、物理的な相互作用を伴う「操作」を教えるのは難しいというものでした。これは「sim-to-real gap」があるためです。シミュレーション環境と現実の環境との間に本質的なずれがあり、シミュレーションで学習したポリシーが現実世界で最適に機能しない原因となります。
このギャップは、これらのタスクが本質的に複雑であるため、器用な操作で最も顕著です。器用さには、視覚レンダリングの忠実度が高く、摩擦や変形といった物理的な微妙な違いをシミュレートするのがより困難です。
遠隔操作データ(テレオペレーションデータ)
遠隔操作データは、人間のオペレーターによるロボットのリモートコントロール中に収集されたデータであり、操作機能を解き放つ鍵として一般的に見なされています。ただし、リソースと運用に多くの労力がかかるため、スケーリングは困難です。
遠隔操作データは、人間のオペレーターがロボット企業が実際に導入で使用しているものとまったく同じ種類のハードウェアを使用してデータを収集している場合に特に役立ちます。これにより、収集されたデータをロボットの物理的な構造(形態)により正確にマッピングできるからです。同様の種類ではあるが厳密には同じではないハードウェアが使用されている場合、そのデータは「オフエンボディメント」と見なされます。これは依然として価値があり、遠隔操作データを補完するのに適しています。遠隔操作データは、カスタムハードウェアの製造が必要になる場合があるため、リソース集約型です。LLMと同様に、ロボットを学習させるにはデータの多様性が必要です。つまり、遠隔操作プロジェクトでは、データの多様性を実現するために、さまざまなセットアップ、背景、照明などが必要となります。対照的に、シミュレーション環境では、すべての物理的要素を調整およびシミュレートできます。
人間のビデオデータ
人間のビデオデータは、ロボットを学習させるための分かりやすい方法のように思えます。インターネット上には膨大な量の既存のビデオデータがあり、人間のビデオデータを作成するのは簡単です。さらに、ロボットは形態学的に人間に似ているように設計されています。ただし、すべての人間のビデオデータがロボット学習用に等しく作られているわけではありません。一人称視点で記録されたビデオ(「撮影者の視点から記録されたビデオデータ」)が最適です。このデータは、カメラを搭載したロボットが「見る」ものに似ています。また、手とオブジェクトの相互作用や人間の意図を理解するのにも役立ちます。
さらに、人間の環境には多様性が豊富にあるため(例:環境、照明、障害物など)、人間のビデオは多様性の問題に役立ちます。ただし、人間の手と腕はほとんどのロボットアーム/マニピュレーターとまったく同じではなく、これらのビデオにはアクションラベルがないことが多いため、一人称視点のビデオは遠隔操作データよりも価値が低いと見なされることがよくあります。
_
上記の要約となりますが、ロボット工学データ会社xdof.aiの創設者は、さまざまなタイプのロボットトレーニングデータを階層に配置する優れたフレームワークを共有しました。

データ収集における最近の進歩
データを使用してモデルを学習またはファインチューニングしている多くのスタートアップと話をして、ロボティクスは非常に多様で論点の多い分野であることに気づきました。データに関して何がうまくいくかについてさまざまなチームが異なる見解を持っており、さまざまなアプローチを試しています。これは、ほとんどのロボティクス専門家が同様の手法に依存していた以前のトレンドサイクルと、今回のロボティクスイノベーションの波との間の重要な違いの一つです。さらに、欠点に対処するために前述の各データアプローチで継続的な研究が行われており、スケーラビリティに関する継続的なブレークスルーにつながり、以前の概念に疑問を投げかけています。
Skild AIは、汎用的なロボティクス基盤モデルを構築するという大胆な野心を持っています。創業者のDeepak PathakとAbhinav Guptaは、「あらゆるロボット、あらゆるタスク、1つの脳」という共通のビジョンを共有しています。彼らは、すべてのタイプのデータを活用する汎用モデル「Skild Brain」を学習させることによって、この目標にアプローチしています。DeepakとAbhinavはどちらも、AIとロボティクスで数十年の経験があり、今日ロボティクスの標準となっているいくつかの主要なアイデアのパイオニアです。彼らは、sim2realに関する最初の主要な受賞論文、ビデオから学習する最初の論文シリーズ(例:VideoDex、およびこちら)、およびいくつかの最大のテレオペレーションデータプロジェクト(MIME、RT-X)に関与してきました。Skild Brainは、シミュレーションと人間のビデオを使用して、移動から操作まで、可能な限り多くの機能とパフォーマンスを実現し、必要に応じて、学習後の遠隔操作で補完しています。
一方、Physical Intelligenceは、ロボティクスにおける器用な操作が要される問題を単独で解決することに焦点を当てています(例:針に糸を通すなど、きめ細かい方法でオブジェクトを操作できること)。最終的な目標は、完全に汎用的なモデル(つまり、タスク全体、ハードウェア全体)を実現することです。彼らはデータアプローチの組み合わせを使用しており、チームは、ロボティクス基盤モデルが効果的に汎用化するためには実世界データが不可欠であると考えています。しかし、現実的であることも重要であり、代替データ(シミュレーションデータ、人間のビデオデータなど)を「代用品」としてではなく「補完」として使用しています(LLMにおける無関係だが有用な事前学習データと同様)。PIは、これにより、過度なエンジニアリング対応を回避し、モデルが代替ソースを、正確なタスク指示ではなく幅広い知識として使用できるようになると考えています。その結果、チームは実世界データの活用に大きく依拠しており、大規模な遠隔操作ラボを運営しています。
Dyna Roboticsも遠隔操作データに焦点を当てていますが、限られた量のデータで製品レベルのパフォーマンスを実現するために、強化学習(Reinforcement learning, RL)アプローチを考案しました。彼らのアプローチの詳細については、次のセクションで説明します。
前述のxdof.aiのような企業は、特殊なハードウェアと汎用ハードウェアを使用して実世界データを収集する大規模な遠隔操作プロジェクトを構築しており、このタイプのデータに対する大きな需要があることを認識しています。Standard Botsは、AIネイティブで垂直統合されたロボットを構築しており、ロボットデータ収集用の独自のハードウェアを開発しました。これにより、顧客は自分でデータを収集し、ロボットにさまざまなタスクを実行するように学習させることができます。
NVIDIAは、データのスケーリングにシミュレーションを活用することを推進しており、シミュレーションをインターネットのビデオデータ、人間のデモンストレーションデータ、および遠隔操作データで補完しています。これは、ヒューマノイド向けのNVIDIA Isaac Groot基盤モデルの基礎となっています。NVIDIAは、ロボティクスにおけるRL用に設計された高性能シミュレーション環境であるNVIDIA Isaac Gymを通じて、シミュレーション環境を顧客に提供しています。これにより、研究者はGPUアクセラレーションを活用して、単一のGPUで数千の環境を同時にシミュレートすることで、複雑なロボットの動作を効率的に学習させることができます。AppleのAIチームも人間のビデオデータで進歩を遂げており、最近、ロボットに器用な操作を教えるための3Dの手と指の追跡データを含む大規模な一人称視点のビデオデータセット「EgoDex」を2025年5月にリリースしました。Appleは、ロボットの学習において、受動的にスケーラブルなデータソースである人間のビデオデータの有効性を示すことを目指しています。
Teslaは最近、ヒューマノイドロボット「Optimus」に、人間のビデオデモンストレーションを利用して、ゴミ箱にゴミを捨てるなどのさまざまな家事を行うように学習させました。
_
どの方法が最も効果的かを判断するのは時期尚早ですが、私たちは以下の点を確信しています。1.シミュレーションと人間のビデオデータは、データパイプラインを費用対効果の高い方法でスケーリングするために、より重要になると考えています。汎用モデルが今後約5〜10年(またはそれより早く)に登場する場合、より高度なシミュレーションプラットフォームと、人間のビデオデータから有用な情報を抽出するためのより洗練されたアプローチが、ほぼ確実に重要な要素になるでしょう。2.遠隔操作データも必要ですが、必要な量を減らす方法があるかもしれません。より少ない量の遠隔操作データで良好なレベルのパフォーマンスを実現できることを期待して、創造的な学習アプローチが見られています。
2) モデル / ロボットポリシー
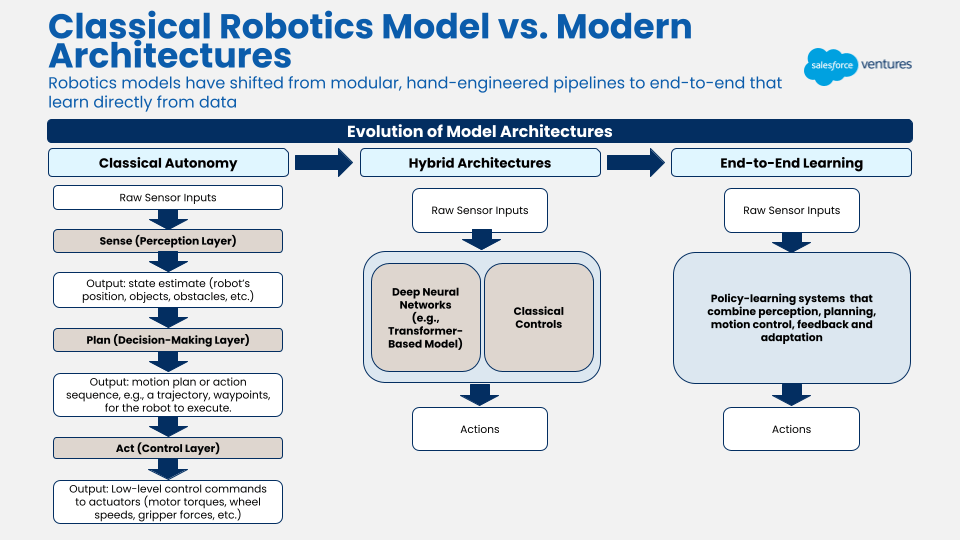
2022〜2023年以前は、ロボットを動かす「モデル」は、より古典的な自律制御ポリシーであり、「センス-プラン-アクト」のモジュール式アプローチが適用されていました。これは、知覚、動作計画、およびモーター制御がそれぞれ別のシステムによって有効になっていることを意味します。このアプローチには、解釈可能性の向上(デバッグが容易)やデータ効率の向上といった利点がありました。ただし、これらのシステムは新しいタスクにうまく汎用化できませんでした。新しいタスクごとに、エンジニアはシステムに新しいルールを書き込む必要がありました。前述したように、汎用性の欠如は、ロボットが世界で大量に導入されていない理由の一つです。
ここで、トランスフォーマーモデルの可能性が注目されます。
トランスフォーマーモデルの台頭により、単一のモデルが生のセンサー入力(画像、LiDAR、または関節位置など)を制御出力(モーターコマンドと軌道)に直接マッピングする、エンドツーエンドのアーキテクチャへの移行が推進されています。これにより、知覚、計画、および制御を個別のモジュールに分離する必要がなくなります。これは汎用化に向けた大きな一歩ですが、トランスフォーマーモデルは非常に多くのデータを必要とします(したがって、前のセクションでデータに重点を置きました)。私たちの投資テーマの一部は、これらのロボティクス基盤モデルを構築する企業に焦点を当てています。
ロボティクスモデルにおける最近の進歩
RFMが過去数年間でどのように進化したかについての包括的な発展の歴史のトピックに入る代わりに、モデルレイヤーにおけるいくつかの最近のブレークスルーを紹介して、現在の最先端技術をお伝えします。急速に増加している進歩の速度は、このリストをすぐに更新する必要があることを意味しますが、現在の状況を理解するのに役立ちます。また、公開されている研究のみを詳細に説明していることに注意してください。最新の最先端技術を一般公開していない企業もいくつかあります。
ここでは、ロボティクス分野でオープンなイノベーションを続けている2つの大手テクノロジー企業、NVIDIAとGoogle DeepMindから始めましょう。
NVIDIAの最新モデル、Isaac GR00T N1.5(2025年5月リリース)は、汎用人型ロボットの基盤モデルです。これは、高レベルの推論と低レベルの制御のために設計されたGR00T N1(2025年3月リリース)のアップデート版です。これは、多くのRFM開発者が採用しているデュアルシステムアーキテクチャを使用しています。システム2(高レベルシステム)は、シーンと指示について「ゆっくり考える」ビジョン・言語トランスフォーマーであり、システム1は、連続的な関節動作を出力する高速な拡散ベースのフロー・トランスフォーマーです。システム2は、カメラ画像と言語コマンドを潜在的な計画に処理し、システム1はその計画を滑らかなモーター軌道に変換します。GR00T N1.5は、実際のロボットのデモンストレーション、人間のビデオ、および膨大な合成データセット(NVIDIA Omniverseを介して生成)の異種混合物でエンドツーエンドで学習されています。このモデルは、マルチモーダル入力を受け取り、高レートの連続的なアクションベクトルを出力します。
GR00Tの重要性は、これが最初のオープンで、完全にカスタマイズ可能な人型ロボットモデルの一つと見なされていることです(Physical Intelligenceのπ₀モデルも同様で、これについては後ほど説明します)。そのデュアルパスウェイは、一般的なビジョン・言語理解と拡散ポリシーアクションジェネレーターを組み合わせています。GR00T N1.5は、合成データを介して、より優れたオブジェクト認識と新しい環境への適応により、N1を改善しています。NVIDIAは、合成モーションデータ(GR00T-Dreamsを介して)を組み込むことで、実際のデータのみを使用した場合と比較して、タスクの成功率が約40%向上したと報告しています。
Google DeepMindのGemini Roboticsモデル(2025年3月に最初にリリース)は、GoogleのGemini 2.0マルチモーダル基盤を基に、具現化されたエージェントを強化します。このファミリーには、2つの主要なモデルが含まれています。
- Gemini Robotics-ER(Embodied Reasoning): 空間的および時間的理解のためにファインチューニングされたビジョン・言語モデル。3D認識に優れており、動作(例:ピックアンドプレースの軌道)のロボット用のコードを生成することもできます。たとえば、ERは、散らかったシーンの画像を取得し、把握ポイントや次のアクションの言語記述を出力できます。
- Gemini Robotics(Vision-Language-Action): ERの推論の上に低レベルの制御を追加する、汎用ビジョン・言語・アクション(Vision-language-action, VLA)モデル。画像と言語指示を受け入れ、タスクを実行するための連続的なアームアクションを出力します。重要なことに、このモデルは器用さの新しい最先端を確立します。滑らかな動きと迅速な完了時間で、複数ステップのタスク(折り紙、カード遊び、サラダ作り)を解決します。オープンなボキャブラリーコマンドを介して、見慣れないオブジェクトや環境も汎用化します。
どちらのモデルもトランスフォーマーベースであり、Gemini 2.0から派生しており、画像と長いテキスト指示をネイティブに解釈できるため、ロボットエージェントの強力な基盤を提供します。Gemini Roboticsモデルにも2つのシステムがあります。Gemini Robotics-ERは、NVIDIA GR00Tのシステム2とほぼ同じ機能(つまり、世界を解釈し、空間的および時間的に推論する)を実行し、Gemini Robotics VLAは、アクションにマッピングするという点でシステム1に似ています。ただし、この分割は、NVIDIAのモデルほど明確で厳密ではありません。NVIDIAのモデルでは、システム2が常にシステム1にフィードされます。
いくつかのスタートアップも、モデルレイヤーで目覚ましい進歩を遂げています。
Skild Brain(2025年7月リリース)は、Skild AIによって開発された汎用ロボティクス基盤モデルであり、さまざまなハードウェアフォームファクター(例:人型ロボット、四足歩行ロボット、マニピュレーターなど)にわたって推論や計画が可能です。チームはSkild Brainを「オムニボディ脳」と呼んでいます。NVIDIAやGoogleと同様の階層型アーキテクチャを利用していますが、まったく同じではありません。低頻度の高レベル操作およびナビゲーションアクションポリシーは、高頻度の低レベルアクションポリシーに入力を提供します。言い換えれば、コマンドを提供する計画/タスクレイヤーと、コマンドを正確な関節角度とモータートルクに変換してロボットの体を駆動するアクションレイヤーです。
DYNA-1(2025年4月リリース)は、スタートアップDyna Roboticsの商用グレードのロボットポリシーであり、信頼性の高い長期間の器用なタスク(例:ナプキンや洗濯物の折り畳み)をターゲットにしています。他のロボットモデルとは異なり、DYNA-1は主に、新しい強化学習(RL)とロボット報酬モデルを使用して開発されました。モデルのアーキテクチャは完全には公開されていませんが、広範な実際の展開でエンドツーエンドで学習されたディープコントロールポリシー(デュアルアームハードウェア上)で構成されています。
DYNA-1は、継続的な運用データで学習されました。重要なイノベーションは、Dynaのカスタム報酬モデルでした。これは、一般的な長期間の器用なタスクの進捗に関する詳細なフィードバックを提供しました(ロボティクス向けで最初の既知のタスク固有の報酬モデル)。これにより、自律的な探索とエラー回復が可能になりました(例:ロボットは、複数のナプキンの引き抜きを自分で検出して修正することを学習します)。数週間かけて、DYNA-1のパフォーマンスは着実に向上しました。安定した動作がわずか数分から、中断のない24時間以上の実行にまで向上しました。Dyna Roboticsの目標は、汎用モデルを構築するために、時間の経過とともにモデルに新しいタスクを追加することです。Skild Brainやここで説明する他のモデルとは対照的に、最初から汎用モデルを目指しているわけではありません。
Physical Intelligence π0.5(2025年4月)は、GR00TやGeminiのようなモデルと同様の野心を持つVLA汎用モデルです。その焦点は、オープンワールドの汎用化です。π0.5は、以前のπ₀モデルを基に構築されていますが、異種のデータミックスで共同学習されています。インターネット規模のビジョン・言語タスク(質疑応答、キャプション、検出)と、大規模なマルチロボット操作デモ(さまざまなアーム、環境)です。そのアイデアは、言語が豊富なWebデータと多くのロボットの例から一度に学習することで、モデルがタスクのセマンティクスを推論し、それらを実行できるということです。π0.5の設計者が説明するように、モデルは「スプーンを柄で持ち上げる方法」(低レベルのスキル)と「家の中で服がどこにあるべきか」(高レベルの常識)の両方を学習します。
- π0.5は、すべてのレベルの動作に単一のトランスフォーマーを使用します。推論では、2段階の「思考の連鎖」プロセスを実行します。まず、モデルはテキストで高レベルのアクションを自己回帰的に生成します(例:「枕を持ち上げる」)。次に、そのテキストを繰り返し使用して、より高い頻度で連続的な関節アクションシーケンスを生成します。内部的には、これにはデュアルコンポーネントが必要です。離散トークン出力用のVLMバックボーンと、連続ベクトル用のより小さなフローマッチング「アクションエキスパート」です。GR00Tには同様の分割がありますが、π0.5は両方の段階でVLMバックボーンを共有しています。
Helix(2025年2月)は、Figureの汎用VLAモデルでもあり、完全な人型の上半身を制御します。その主な目標は、継続的な全身出力、マルチロボットコラボレーション、およびオンデバイス展開です。Helixは、分離されたシステム1 / 2設計も採用しています。システム2は、カメラ画像とロボットの状態(エンドエフェクターのポーズ、指の位置)を言語コマンドとともに取り込み、セマンティックな潜在的埋め込みを生成します。システム1は、マルチスケール畳み込みビジョンバックボーンを備えたトランスフォーマーモデルです。システム1は、システム2から同じ画像と状態入力を受け取り、アーム、胴体、指の両方に対して連続的な関節アクションを直接出力します。
- Helixは、完全な上半身制御を実証しています。手首、胴体、指を同時に操作できます。34次元で連続的な制御を直接出力することにより、低次元のアクショントークンを回避します。また、マルチロボット制御も紹介しました。同じニューラルネットの重みを使用して、共同タスク(食料品の片付け)で2台のロボットを同時に制御しました。これは、同じポリシーで複数のロボットを同時に制御できることを示しています。
_
汎用モデルの実現は、課題の一部にすぎません。これらのモデルを現実世界に導入するには、企業は明確なハードウェア戦略も必要です。独自のハードウェアを設計するか、パートナーから既存のコンポーネントを活用するかです。最も重要なのは、ハードウェアとソフトウェアが密接に連携して開発されることです。物理的なフォームファクターとAIモデル間の緊密なフィードバックループが重要です。カスタムハードウェアがすべての場合に必要であるとは限りませんが、既存のフォームファクターが必要なタスクをサポートしていない場合は、明確な利点を提供できます。
3)ハードウェア
ハードウェアは、モデルやデータと同様に、ロボティクスの進歩において重要な要素です。実際、ロボットソフトウェアと並行したハードウェアの進化は、広範な導入にとって不可欠になります。以下は、私たちが言及する価値があると考えている興味深いハードウェアイノベーションの最近のハイライトの概要です。ハードウェアコンポーネントの詳細については、SemiAnalysisの最近の投稿が素晴らしいです。
ロボットハードウェアの最近のブレークスルーは、主に3つの異なる分野に焦点を当てています。より手頃な価格、より堅牢、そしてより機敏で器用なハードウェアです。
- 手頃な価格:ロボットを大量に導入するには、顧客の投資対効果(ROI)に訴求できる価格で販売する必要があります。これは、部品表(the bill of material, BOM)コストを削減する必要があることを意味します。BOMコストが10万ドルを超えるロボットが見られ、それが高い販売価格につながっています。これらのロボットが通常自動化するタスクの種類(多くの場合、「汚い、危険、退屈」なタスク(例:化学プラントの検査)とラベル付けされています)の場合、代替手段は、採用が困難または離職率が高い人間の労働力を雇用することです。その結果、ロボットの価格は、同等の人間の労働力のコストを下回るか、同程度に抑える必要があります。
- 堅牢性:ROIの重要な推進力は、ロボットが最小限の人的介入で継続的に動作できる能力です。これは、ロボティクスの世界で「堅牢性」と呼ばれています。たとえば、ロボットが「バグ」を出したり、充電したりすることなく、16時間または24時間連続して(作業者の2つまたは3つ分のシフトをカバーして)実行できる場合、明確な経済的価値を提供します。堅牢性を実現するには、バッテリー寿命の向上と、より耐久性のあるハードウェアが必要です。ただし、ハードウェアだけでは不十分です。堅牢性の多くは、システムを強化する基盤モデルの性能に依存します。
- 敏捷性/器用さ:特定の動作や動きを実行できるようにするには、ロボットアーム、手、胴体、脚に十分な自由度(degrees of freedom, DOF)が必要です。これは、ロボットが独立して動ける方法を表します。各自由度は通常、1つの独立した運動軸に対応します。たとえば、関節ヒンジ(肘や膝など)の単一のDOFは、上下にしか移動できないことを意味しますが、2つのDOFは、手首のように、上下だけでなく左右にも移動できることを意味します。また、これらの動きを可能にするモデルは、ハードウェアと連携して、そのDOFを理解し、高レベルの計画を低レベルのアクションに変換する方法を理解する必要があります。上記で説明したように、操作スキルへの関心が高まるにつれて、器用な手のデザインはより複雑になっています。また、ダンス、ランニング、バク転などができる人型ロボットのデザインも見られます。
アクチュエーターとセンサー
人型ロボットが主流の世界では、強力で応答性が高く、エネルギー効率の高いアクチュエーターが必要です。アクチュエーターは、ロボットを動かし、電気信号を物理的な動きに変換するデバイスです。それらをロボットの筋肉と考えてください。より軽量で、より強力で、より柔軟なアクチュエーターの開発は、現在および将来のロボットシステムにとって非常に重要です。
Boston DynamicsのAtlasのAtlas人型ロボットは、古い油圧システムを置き換える完全電気アクチュエーターを備えています。電気アクチュエーターはコンパクトでありながら強力で、Atlasがより効率的に、より少ない複雑さで幅広い動きを実行できるようにします。より複雑で高価で、液漏れしやすい油圧アクチュエーターからのこの移行は、より持続可能で保守しやすいシステムへの業界の推進力を表しています。
センサーは、効果的にロボットシステムの役割を担い、ロボットの制御ポリシーに供給される視覚入力を記録します。低コスト、高解像度のRGB-Dカメラ(色と深度の両方をキャプチャ)がより一般的になり、RT-2やDYNA-1のようなVLM駆動の知覚システムの基盤となっています。
触覚センサーの進化により、ロボットに触覚が追加され、ロボットの器用さが向上し、ロボットが圧力、テクスチャー、接触を感じることができるようになりました。Amazonのピックアンドプレースロボット「Vulcan」は、掴むオブジェクトを感じることができるようになり、倉庫アイテムの最大75%を処理できます。
バッテリー
バッテリーの化学的性質の進歩、より優れた電力管理、およびハードウェア効率の向上により、バッテリー寿命は近年大幅に向上しています。TeslaのOptimusは、3度の設計改良を経てバッテリーを2.3 kWhから3 kWhに改善しました。これは、工場で1回の充電で最大8〜10時間持続できることを意味し、人間のフルシフトに耐えることができます。Figureは、Figure 02の胴体に統合されたバッテリーパックをアップグレードしたため、ロボットは5時間動作でき、Figure 01と比較して動作時間が50%増加しました。
興味深い技術的な実例として、バッテリーと人型ロボットの設計が最近、北京の人型ロボットハーフマラソンレースでストレステストされました。バッテリーの故障、過熱などが原因で、21台のロボットのうち6台しかレースを完走できませんでした。しかし、Tiangong Ultraは、バッテリー交換を3回だけで2時間40分でレースを完走しました。これは、そのような距離を走るロボットにとっては目覚ましい偉業であり、同じロボットが1年前にレースを完走するのにかかった8時間から大幅に改善されました。
遠隔操作ハードウェア
以前、データ収集とモデル学習の観点から、遠隔操作の重要性について説明しました。高度な遠隔操作インターフェースにより、人間は精度と最小限の遅延でロボットを制御することが容易になりました。汎用VRヘッドセットやGELLOのような安価なセットアップにより、遠隔操作がより身近になりましたが、ハードウェアイノベーションは引き続きこの分野を推進しています。最先端の遠隔操作ハードウェアは、触覚フィードバックシステムを備えており、オペレーターに触覚を与え、精度を向上させ、エラーを減らします。DOGloveは、今年のICRA(International Conference on Robotics and Automation)でデビューした、器用な遠隔操作用に設計されたオープンソースの低コスト触覚グローブです。HOMIEは、腕、手袋、フットペダルを組み合わせた外骨格遠隔操作ハードウェアで、移動と操作の遠隔操作用です。
ハンドテクノロジー
ICRAは2025年をロボットハンドの年と宣言しました。いくつかの研究グループが、手の中でペンを回したり、トランプを配ったりするなどのタスクを実証する、手内操作が可能なハンドを展示しました。特に、Sharpa Roboticsは、会議で22の自由度と高度な触覚センシングを備えたロボットハンドをデモしました。標準的なパラレルグリッパーは、操作タスクのかなりの部分を実行できますが、より高度な人間のようなロボットハンドは、高度に器用なタスクに必要であると多くの人が考えています。ただし、これはまだ未解決の研究課題です。
補足として、人間の手には27の自由度があり、22の自由度はそれに近いレベルです。そのレベルの器用さを持つロボットハンドは、Clone Roboticsしか聞いたことがありません。これは、「最も生体模倣的な手」である合成素材で作られたロボットハンドも誇っています。Tesla OptimusやShadow Robotなど、他のいくつかのロボティクス企業も、ますます高度な器用さを持つ手に取り組んでいます。
ヒューマノイドロボット
ロボットシステムのフォームファクターとしての人型ロボットは、近年人気が高まっています。その背景にある議論は、世界は人間のために設計されているため、人間が行うことを行う汎用的なロボットシステムを持つには、形態が類似したフォームファクターが必要であるということです。これは複雑な取り組みですが、有望な進展が見られています。
Figureは、高度にカスタマイズされたヒューマノイドのフォームファクターを構築しており、アクチュエーター、センサー、バッテリー、電子機器に至るまですべてを自社で製造しています。それらはBotQ施設で製造および組み立てられています。Figure 02は、2024年8月に発表に発表され、人間の手の動きを綿密に模倣し、最大25 kgの物体を持ち上げることができる16自由度を提供する再設計された手を備えています。そして、Figure AIは、第3世代のヒューマノイドロボット「Figure 03」を積極的に開発しています。
Tesla Optimusも、完全に垂直統合されたサプライチェーン(Tesla車と同様)を備えた、高度にカスタマイズされたヒューマノイドを構築しています。最新のモデル「Optimus Gen-3」は、大幅な改良が加えられており、高度に連結された22の自由度を持つ手など、微妙な操作や、空中にある物体をキャッチするなどのタスクを可能にします。敏捷性とバランスを向上させるために、Teslaは関節の形状、特に足首と腕を再設計し、より自然で滑らかな動きをサポートしています。さらに、Optimusは、回転運動を効率的かつ最小限の摩擦で直線運動に変換する、腱駆動ボールねじトランスミッションのような斬新な駆動メカニズムを採用しています。xAIのGrok会話型AIとの統合により、その機能がさらに強化され、シームレスな人間のようなインタラクションが可能になります。
Unitreeの継続的なハードウェアのイノベーションは、高度なロボティクスをはるかに身近にするのに役立っています。たとえば、彼らのG1ヒューマノイドは、わずか16,000ドルから始まります。彼らのヒューマノイドと四足歩行プラットフォームの両方には、最先端の深度センシングおよび知覚システムが装備されています。G1には、バランス、視覚、および物体検出のためのAIが組み込まれており、主に愛好家や研究者によって使用されています。対照的に、Unitreeの主力H1ロボットモデルは、より強力なヒューマノイド設計であり、大幅に高い計算能力と自由度を備えており、高度な研究開発や基盤モデルのファインチューニングに適しています。
これらは、この領域の複雑さを考えると、決して包括的な概説ではありません。言及する価値のあるヒューマノイドロボティクスを開発している他の企業は、1XとClone Roboticsであり、どちらもソフト外骨格を備えた洗練されたヒューマノイドのフォームファクターを設計しています。
過去のロボティクスサイクルからの教訓
今日のロボティクス企業は、技術的な進歩に加えて、以前のイノベーションサイクルの失敗やつまずきから学んでいます。歴史的に、ロボティクス企業は、多額のベンチャーキャピタルからの投資にもかかわらず、商業的な期待に応えられなかったと言えます。この新しいロボティクス時代に向けて、以前のサイクルからの教訓、つまり何がうまくいかなかったのか、そして今何が違うのかを振り返ることが重要です。
自動運転車の満たされなかった約束

自動運転車の誇大広告サイクルは2015年から2020年にピークを迎え、数十億ドルのベンチャーキャピタルの投資がCruiseやZooxのような企業に注ぎ込まれました。市場は数年後に大規模な完全自動運転車を期待していましたが、Waymoは特定の都市で普及しているものの(そして楽しい体験を提供しますが)、レベル4の自律性しか達成していません(つまり、ドライバーは不要ですが、その利用は特定のエリアに限定されています)。同様に、TeslaのFSDは、ドライバーが常に完全に注意を払う必要があります。
自動運転車が直面する主な課題の一つは、ロングテール(滅多に起きない事象)のエッジケースを解決することが非常に難しいことです。自動運転車はオープンワールドで動作するため、予測不可能な行動をとる歩行者や不規則な運転行動など、対処が難しいエッジケースの非常に長いテールが存在します。自動運転車は、 分布外(out of distribution, OOD)のシナリオに遭遇して失敗することがよくあります。Cruiseを含む多くの企業は、これらのエッジケースが解決されるまで、より多くのデータを収集するだけでこの問題を解決しようとしています。これが、自動運転車の実現に予想よりも時間がかかっている主な理由です。自動運転車が安全性とパフォーマンスの保証を満たすために必要なエッジケースのロングテールを考慮するのに十分なデータを取得するには、長い時間がかかります。多くのロボットは自動運転車と比較してはるかに構造化された環境に導入される可能性がありますが、消費者向け環境に取り組むチームは自動運転車業界と同様の問題に遭遇する可能性があります。

A
自動運転車業界を悩ませているもう一つの課題は、これらの企業が過大な約束をしたが、実際には期待に応えられなかったことです。Tesla、Waymo、Uberなどは、レベル4の自律性をいつ達成するかについて繰り返し期待を高めてきましたが、予想以上に時間がかかっています。派手なデモは、実際の導入を代表するものではなく、自動運転車に対する国民の信頼と熱意を損ないました。これが、多くのロボティクス創業者が、一般の期待を設定する際には慎重になるべき理由です。
迅速かつスケーラブルな展開が重要
機能するロボットを持っているだけでは不十分です。企業は、パイロット段階を超えて進むために、反復可能でスケーラブルな導入方法を確立する必要があります。2014年から2015年の時代の多くのロボティクス企業は、各顧客に対して「ワンオフ」(一回限りの)統合を実行することに行き詰まり、より広範な実装とスケールへの明確な道筋がないという間違いに陥りました。この以前のイノベーションの波からのいくつかの企業に話を聞いたところ、彼らの最大の間違いは、AIモデルとロボットの構築よりも、導入に関するエンジニアリング作業に多くの時間を費やしたことでした。困難ではありますが、ロボットは最小限の再構成でさまざまな環境に適応するように設計されるべきです。チームはまた、社内の能力またはシステムインテグレーターとのパートナーシップを通じて、導入を成功させるためのリソースを確保する必要があります。
ロボットの適応性と導入の容易さは、ロボットとその基盤となるモデルの両方がどれだけ汎用化可能かにかかっています。以前の世代のロボティクス企業は、さまざまな設定/顧客環境で汎用化できるモデルやロボットポリシーを持っていなかった可能性があり、その結果、長くて困難な導入作業につながりました。真に汎用的な堅牢なロボティクス基盤モデルを使用すれば、これは問題ではなくなる可能性があります。
タイミングがすべて
以前の波からの多くのロボティクス企業は、単に時期尚早でした。彼らは、今日のハードウェア効率、スケーラブルなデータ収集方法、およびAI機能を持っていませんでした。これらの主要分野での技術的進歩は、当時うまくいかなかったことの多くが現在技術的に可能であることを意味します。
現在におけるロボティクスの可能性
私たちはまだ真に主流のロボティクスからは遠い段階にいますが、ロボット学習データ、ロボットモデル、およびロボットハードウェア全体の進歩の速度は、有意義な形で加速しています。現在の傾向が続けば、自動運転車が大規模に普及するのを見るよりも早く、汎用ロボットが現実の世界に導入される可能性が高くなります。
要するに、ロボットの時代が来ていると言えます。そして、そのスピードは速いです。私たちは、RFM、フルスタックのハードウェア/ソフトウェアソリューション、およびロボティクスツールのより広範なエコシステム(データプロバイダー、シミュレーションプラットフォームなど)全体でこの成長を支援できることを楽しみにしています。次の記事では、この分野に関心のある投資家の皆さまにフレームワークを共有できればと思い、ロボティクスへの投資アプローチについて詳しく説明します。
私たちは過去7ヶ月間、ロボティクスの世界に没頭してきましたが、まだ表面をなぞったにすぎません。ロボティクスは、私たちがこれまでに出会った中で最も難しい技術分野の一つです。上記の私たちの見解について、皆さまのフィードバックをお待ちしています。そして、皆さまがもしロボティクスソリューションを構築しているのであれば、私たちは皆さまの事業についてもっと知りたいと思っています。Emily Zhao(emily@salesforceventures.com)およびPascha Hao(pascha@salesforceventures.com)にメールしてください。





