
AI Infrastructure Explained
March 20, 2024


Innovative applications of AI have captured the public’s imagination over the past year and a half. What’s less appreciated or understood is the infrastructure powering these AI-enabled technologies. But as foundational models get more powerful, we’ll need a strong technology stack that balances performance, cost, and security to enable widespread AI adoption and innovation.
As such, Salesforce Ventures views AI infrastructure as a crucial part of the market to build and invest in. Within AI infrastructure, a few key elements are most critical: Graphic Processing Units (known as “GPUs”), software that enables usage of GPUs, and the cloud providers that link the hardware and software together.
Understanding these three elements—how they work, how they’re delivered, and what the market looks like—will help founders and innovators execute more effectively and identify new opportunities. In this write-up, we present our analysis of the AI infrastructure stack, starting with the basics of GPUs and software components and moving to the ways products are delivered and how the market is segmented.
GPU Hardware
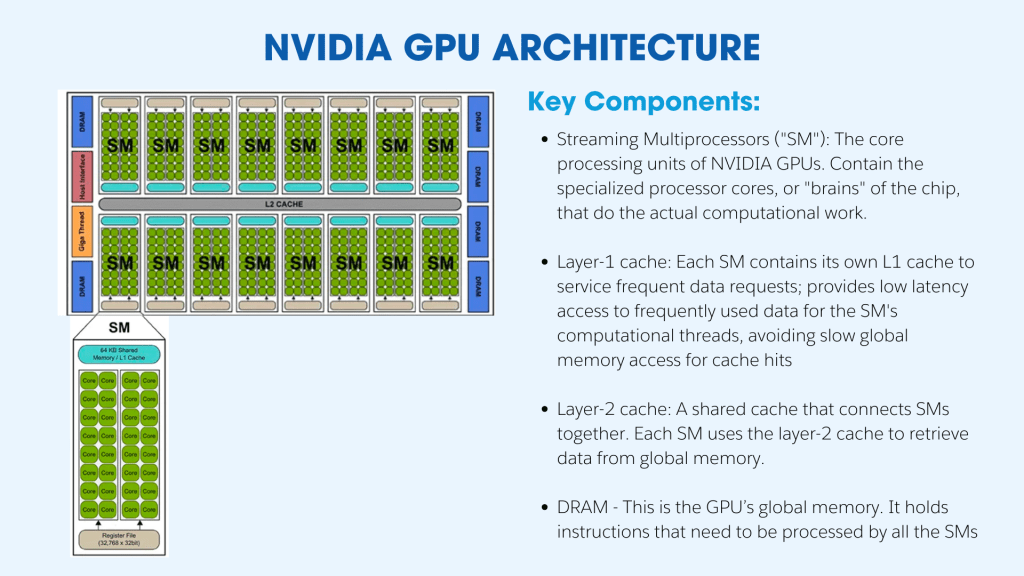
GPUs are the hardware that powers AI.
While many traditional servers utilize computer processing units (CPUs), these processors aren’t designed to support parallel computing, which is needed for specialized tasks like deep learning, video gaming / animations, autonomous vehicles, and cryptography. The key difference between GPUs and CPUs is that CPUs have fewer processing cores, and these cores are generalized for running many types of code. GPU cores are simpler and specialized for data-parallel numerical computations, meaning they can perform the same operation on many data points in parallel.
GPUs are organized into nodes (single server/computing unit), racks (enclosures designed to house multiple sets of computing units and components so they can be stacked), and clusters (a group of connected nodes) within data centers. Users have access to the GPUs at these data centers through virtualization into cloud instances. Data centers that house GPUs must be configured differently than traditional CPU data centers. This is because GPUs require much higher bandwidth for communication between nodes during distributed training, making proprietary interconnects such as InfiniBands necessary.
The density of GPU servers and their high power draw calls for planning around power provisioning, backup, and liquid cooling to ensure uptime. Further, the topology (physical interconnection layout) of GPUs is also different from CPUs—GPU interconnect topologies are specially designed to deliver maximum bi-sectional bandwidth to satisfy the communication demands of massively parallel GPU workloads. By contrast, CPU interconnects focus more on low-latency data sharing.
In terms of GPU manufacturers, NVIDIA currently dominates with an 80%+ market share. Other noteworthy players include AMD and Intel. Demand for GPUs currently far outweighs supply, prompting intense competition amongst manufacturers and encouraging customers to experiment with building their own AI chips.
Aside from big tech companies, there are also a few startups attempting chip design. These new entrants are oftentimes focused on optimizing the design for specific use cases or AI workloads. For example, Groq’s LPU (Language Processing Unit) is solving for cost-effective latency, and Etched’s Sohu chip is designed to run transformer-based models efficiently. We’re excited to see the innovation in the space and market supply and demand dynamics at work.
GPU Software
Supporting these GPUs are the various software solutions that interact directly with the GPU clusters and are installed on different levels (i.e., nodes, racks, or clusters). The following is a non-comprehensive list of the types of software associated with GPU workloads:
- Operating systems: The operating system handles the scheduling of processes and threads across CPUs and GPUs. It allocates memory and I/O appropriately. Examples of GPU operating systems include CentOS, RHEL, and Ubuntu.
- GPU drivers: GPU drivers are vendor-provided parallel computing platforms that control the GPU hardware. Examples of GPU drivers include NVIDIA, CUDA, and the open-source AMD ROCm.
- Cluster management / job scheduling: Cluster management software allocates GPUs to submitted jobs based on constraints and availability, distributes batch jobs and processes across the cluster, manages queues and priorities for diverse workloads, and integrates with provisioning tools. Examples include Kubernetes and Slurm.
- Provisioning tools: Provisioning tools provide containers / isolated environments for applications or jobs to run on the cluster and allow for portability to different environments. Examples include Docker and Singularity.
- Monitoring software: Monitoring software tracks specialized metrics and data specific to AI operations. Examples include Prometheus, Grafana, and Elastic Stack.
- Deep learning frameworks: Frameworks that are specifically designed to take advantage of GPU hardware. These are essentially libraries for programming with tensors (multi-dimensional arrays that represent data and parameters in deep neural networks) and are used to develop deep learning models. Examples of deep learning frameworks include TensorFlow and PyTorch.
- Compilers: Compilers are development environments to build optimized code. Examples include the NVCC compiler for NVIDIA’s CUDA code and HCC/HIP compilers for AMD ROCm GPU code.
These softwares help infrastructure teams provision, maintain, and monitor GPU cloud resources.
The hardware / software combination matters a lot for the type of AI workloads being performed. For example, distributed training (training an AI model as fast and effectively as possible) typically requires multiple servers with best-in-class GPUs and high node-to-node bandwidth. Meanwhile, production inference (running the job of an AI application) needs GPU clusters that are configured in a way to handle thousands of requests simultaneously, usually relying on optimized inference engines like TensorRT, vLLM, or proprietary stacks, such as Together AI’s Inference Engine.
In the next section, we provide an overview of what we consider the current landscape of cloud infrastructure that can accommodate various AI workloads.
The 3 Types of GPU Cloud Providers

Salesforce Ventures’ view of the market is that there are currently three types of GPU cloud providers. Each provider has its own benefits depending on the desired use case.
Hyperscalers
The first type of GPU cloud provider are Hyperscalers: cloud computing providers that operate massive, globally distributed data centers and cloud infrastructure and offer a wide array of computing services. While Hyperscalers haven’t historically focused on GPUs, they’ve recently expanded their offerings to GPUs to capture the immense market demand for AI technologies. Notable Hyperscalers include household names like AWS, Google Cloud, Azure, Oracle, and IBM Cloud.
In terms of infrastructure, Hyperscalers own their GPUs but co-locate these GPUs with colocation data center operators or maintain their own data centers where their chips are housed. Software provided by Hyperscalers is largely product dependent—some might have lower-level software just for managing GPU clusters, while others provide higher-level abstractions that are MLOps focused.
For example, AWS has EC2 instances that offer different types of GPUs (e.g., T4, A10, A100, H100, etc.) as well as deep learning software solutions (e.g., AWS Deep Learning AMIs) that include the training frameworks, dependencies, and tools developers can utilize to build and deploy models. Meanwhile, AWS Bedrock offers API endpoints of popular open-source and closed-source models, abstracting away the interim steps of deployment.
Specialized Cloud Providers
The second type of GPU cloud provider is what we call “Specialized Cloud Providers.” Unlike Hyperscalers, these organizations are focused on providing GPU-specific infrastructure for AI and high-performance computing workloads. Examples of specialized cloud providers include CoreWeave, Lambda Labs, Massed Compute, Crusoe, and RunPod.
Like Hyperscalers, Specialized Cloud Providers own their GPUs, but either co-locate them with colocation data center operators or operate their own data centers. These providers either offer bare-metal GPU clusters (hardware units networked together) or GPU clusters with a basic software layer that enables users to operate the clusters and virtualization layers to spin up cloud instances—similar to the EC2 instances at AWS.
Both Hyperscalers and Specialized Cloud Providers require massive upfront capital outlays to buy and install the GPUs in their data centers, and sometimes build and operate the data centers themselves (if they’re not “colocated”).
Inference-as-a-Service / Serverless Endpoints
The third type of GPU cloud provider encompasses a broader array of companies that we bucket under “Inference-as-a-Service” or “Serverless Endpoints.” These are newer entrants to the market that offer software abstraction on top of GPU clouds so users only interact with the API endpoints where models are fine-tuned and deployed for inference. Examples of companies in this space include Together AI, which we recently led a round of financing in, Fireworks.ai, Baseten, Anyscale, Modal, OctoML, Lepton AI, and Fal, among others.
Most Inference-as-a-Service providers get their GPUs from Hyperscalers or Specialized Cloud Providers. Some rent GPUs and make a margin on top of the unit cost, some form revenue-sharing partnerships, and some are pure passthrough (i.e., revenue goes directly to the GPU supplier). These companies typically have a software layer with the highest level of abstraction so that users likely don’t have visibility into what GPU cloud provider or specific SKU of GPU/networking configuration is utilized. Users also rely on these companies to perform MLOps-type value-adds such as autoscaling, resolving cold starts, and maintaining the best performance possible. Oftentimes, Serverless Endpoint companies build their own proprietary stack of optimizations to improve cost and performance (often a balance between latency and throughput).
Inference-as-a-Service has gained traction with the new wave of generative AI because these providers take away many steps around provisioning and maintaining infrastructure. If a startup opted to use a product from a cloud vendor, it’d likely need to:
- Select a GPU instance (based on model performance requirements),
- Launch that instance,
- Install and set up the necessary software (e.g., GPU drivers, deep learning libraries),
- Containerize the model,
- Transfer the container to the EC2 instance,
- Install serving software depending on model format and deployment requirements, and
- Configure the serving software to load the model and expose it as an API endpoint.
However, if a startup was to deploy an LLM with a provider like Together AI, all it’d need to do is select the relevant model from the Together Playground, launch the model using the serverless endpoint provided by Together AI, and build the inference endpoint into a generative AI application using the API key and Python/Javascript SDK. Together AI also performs maintenance for its users.
Also note that some players in this broad category offer products targeting distributed training workloads, including Together AI and Foundry. Given the need for larger GPU clusters to train models (vs. serving/running inference), these products have a different form factor from Serverless Endpoints.
Organizing AI Infrastructure
We hope our organization of the current AI infrastructure stack can inform founders on how to orchestrate their own infrastructure and spark ideas for how to innovate and improve upon the current technologies. In our next post, we’ll dive deeper into the viability of the various types of GPU cloud providers, and detail where we see opportunities for innovation.
—
If you’re a founder building in AI, we’d love to talk. Salesforce Ventures is currently investing in best-in-class AI tooling and horizontal or vertical applications. To learn more, email me at emily@salesforceventures.com







